Github项目地址传送门
项目相关要求
- (完成)使用 -n 参数控制生成题目的个数。
- (完成)使用 -r 参数控制题目中数值(自然数、真分数和真分数分母)的范围。该参数可以设置为1或其他自然数。该参数必须给定,否则程序报错并给出帮助信息。
- (完成)生成的题目中计算过程不能产生负数,也就是说算术表达式中如果存在形如e1 − e2的子表达式,那么e1 ≥ e2。
- (完成)生成的题目中如果存在形如e1 ÷ e2的子表达式,那么其结果应是真分数。
- (完成)每道题目中出现的运算符个数不超过3个。
- (完成)程序一次运行生成的题目不能重复,即任何两道题目不能通过有限次交换+和×左右的算术表达式变换为同一道题目。例如,23 + 45 = 和45 + 23 = 是重复的题目,6 × 8 = 和8 × 6 = 也是重复的题目。3+(2+1)和1+2+3这两个题目是重复的,由于+是左结合的,1+2+3等价于(1+2)+3,也就是3+(1+2),也就是3+(2+1)。但是1+2+3和3+2+1是不重复的两道题,因为1+2+3等价于(1+2)+3,而3+2+1等价于(3+2)+1,它们之间不能通过有限次交换变成同一个题目。生成的题目存入执行程序的当前目录下的Exercises.txt文件。
- (完成)在生成题目的同时,计算出所有题目的答案,并存入执行程序的当前目录下的Answers.txt文件。
- (完成)程序应能支持一万道题目的生成。
- (完成)程序支持对给定的题目文件和答案文件,判定答案中的对错并进行数量统计, 统计结果输出到文件Grade.txt。
代码规范
本次项目的代码遵循了谷歌代码规范(C++),但由于谷歌代码规范篇幅太多,所以我们目前只遵循了其中的部分规范,具体如下:
- 禁止使用宏
- 分号以前不加空格
- 行宽原则上不超过80
- 一行只定义一个变量
- 左大括号前保留一个空格
- if, else前后都要一个空格
- for, while后要有一个空格
- return 后面的数值不加 ( )
- 每个文件应该含有版权信息及作者
- 左圆括号之后和右圆括号之前无空格
- 函数参数过多时,每行的参数变量对齐
- 一目运算符与变量之间不加空格符隔开
- 禁止使用 using 指示(using-directive)
- 禁止使用C++的流,而是用printf之类的替代
- 要么函数名与参数同行,要么所有参数并排分行
- 换行代码缩进2个空格,并且使用两个空格符取代制表符
- 二目以上的运算符与变量,常量之间用空格隔开(各类括号除外)
- 不论控制语句,循环语句后面的循环体有多少行,都必须使用花括号
- 普通函数,类型(含类与结构体,枚举类型),常量等使用大小写混合,不含下划线
- 除函数定义的左大括号可置于行首以外,包括函数/类/结构体/枚举声明,各种语句的左大括号必须置于行末,所有右大括号独立成行
设计思路
具体设计&关键代码
ImproperFraction类
构建一个ImproperFraction的类,然后重载这个类的四种运算 +-x÷ 以及以及六种逻辑关系**’<’ ‘==’ ‘<=’ ‘!=’ ‘>’ ‘>=’**判断,在后续的代码编写之中都是基于这个类进行运算
核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| class ImproperFraction {
public :
ImproperFraction(){}
ImproperFraction (int Mole, int Deno, int Coef = 0) {
int g = std::__gcd (Mole, Deno);
g = std::max(g, 1);
mole = (Mole + Coef * Deno) / g;
deno = Deno / g;
}
ImproperFraction operator + (const ImproperFraction & rhs ) const {
int DENO = deno * rhs.deno;
int MOLE = mole * rhs.deno + rhs.mole * deno;
ImproperFraction res = ImproperFraction (MOLE, DENO);
return res;
}
ImproperFraction operator - (const ImproperFraction & rhs ) const {
int DENO = deno * rhs.deno;
int MOLE = mole * rhs.deno - rhs.mole * deno;
ImproperFraction res = ImproperFraction (MOLE, DENO);
return res;
}
ImproperFraction operator * (const ImproperFraction & rhs ) const {
int DENO = deno * rhs.deno;
int MOLE = mole * rhs.mole;
ImproperFraction res = ImproperFraction (MOLE, DENO);
return res;
}
ImproperFraction operator / (const ImproperFraction & rhs ) const {
int DENO = deno * rhs.mole;
int MOLE = mole * rhs.deno;
ImproperFraction res = ImproperFraction (MOLE, DENO);
return res;
}
bool operator < (const ImproperFraction & rhs ) const {
return mole * rhs.deno < rhs.mole * deno;
}
bool operator == (const ImproperFraction & rhs ) const {
return mole * rhs.deno == rhs.mole * deno;
}
bool operator != (const ImproperFraction & rhs ) const {
return !(mole * rhs.deno == rhs.mole * deno);
}
bool operator <= (const ImproperFraction & rhs ) const {
return (*this) < rhs || (*this) == rhs;
}
bool operator > (const ImproperFraction & rhs ) const {
return !((*this) <= rhs);
}
bool operator >= (const ImproperFraction & rhs ) const {
return (*this) > rhs || (*this) == rhs;
}
private :
int mole = 0;
int deno = 1;
};
|
题集的生成
表达式的生成
在这里选择的是rand() 随机生成 运算符个数,类型以及每个被运算的数值。
表达式的合法性判断
在生成过程之中,有两个要点会导致表达式非法
1.运算过程中出现负值
2.在÷运算后面出现0
解决办法:两个特殊判断即可
表达式的去重
表达式的重复有两种情况:
1.完完全全的重复,如出现两个1 + 2 + 3 的表达式
2.运算顺序上的重复,如:
1 + 2 + 3 和 2 + 1 + 3重复
2 + 3 x 4 和 4 x 3 + 2重复
解决办法:
对于(1)的情况只需要将生成的表达式保存进C++STL的set之中即可自动去重。
对于(2)的情况,则是按照一定规则生成表达式来避免这一情况,规则如下:
1.默认左边的运算符的优先度高于右边
2.第一个数字一定不小于第二个数值
因此1 + 2 + 3和2 + 3 x 4不会被生成,而只会生成2 + 1 + 3和4 x 3 + 2
题集无法生成要求的数量
例如:
传入的参数是 -n 10000 -r 1 的时候,很明显无法生成10000道题目,因此陷入死循环的生成中
解决办法:
设置一个时间戳time,当生成表达式的部分循环了1000000次之后自动跳出循环,终止生成表达式
答案的生成
在表的是合法性判断的时候,会判断最终的数值是否小于0,在这里就已经计算标准答案,保存并打印到answer.txt即可
核心代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
| void questionSetGenerate (int limit, int number) {
std::set<std::string>expressions;
std::vector<std::string>exercise;
std::vector<ImproperFraction>answer;
ImproperFraction zero = ImproperFraction(0, 1);
int time = 0;
while (expressions.size() < number && time < 1000000) {
time ++;
int sz = expressions.size();
int opnumber = rand() % 3 + 1;
ImproperFraction a[5];
ImproperFraction res = ImproperFraction(0, 1);
const ImproperFraction zero = ImproperFraction(0, 1);
char op[4];
for (int i = 0; i <= opnumber; i++) {
a[i] = ImproperFraction(rand() % (limit * limit), std::max(1, rand() % limit));
if (i) {
op[i] = oper[rand() % 4];
}
}
std::string exp = "";
bool flag = true;
if (a[0] < a[1]) {
std::swap (a[0], a[1]);
}
for (int i = 0; i <= opnumber; i++) {
if (i) {
if (op[i] == '+') {
res = res + a[i];
} else if (op[i] == '*') {
res = res * a[i];
} else if (op[i] == '-') {
res = res - a[i];
} else {
if (a[i] == zero) {
flag = false;
break;
}
res = res / a[i];
}
exp = exp + ' ';
exp = exp + op[i];
exp = exp + ' ';
} else {
res = res + a[i];
}
fractionToString(a[i], exp);
if (res.getdeno() < 0 || res.getmole() < 0) {
flag = false;
break;
}
}
if (flag) {
expressions.insert(exp);
if (expressions.size() > sz) {
exercise.push_back(addbrackets(exp));
answer.push_back(res);
}
}
}
}
|
答案正确性的检测
用户通过参数-e exercises.txt -a answers.txt,传进来了题目文件的名称和答案文件的名称。
首先,由于文件可能不存在或者没有访问的权限,我们需要对此进行检查,假如有错误,则进行报错,没有异常才进行下一步。
第二步,我们需要对exercises.txt文件中的题目计算一遍,然后再和answers.txt文件中的答案进行比较。题目的计算分两步进行,即先将中缀表达式转化为后缀表达式,然后计算后缀表达式的答案。
对于这个函数,我们考虑了exercises.txt行数和answers.txt行数不相等的情况,此时我们将以exercises.txt的行数为准,假如answers.txt行数过少,那么将视为错误答案,假如过多,那么将被忽略。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
|
void checkAnswer(FILE *exerciseFile, FILE *answerFile) {
FILE *pFile = getPointerToGradeFile();
int problemID = 0;
char answer[256];
char exercise[256];
std::vector<int> wrongID;
std::vector<int> correctID;
while (fgets(answer, 256, answerFile)) {
if (!fgets(exercise, 256, exerciseFile)) {
break;
}
problemID++;
removeRedundantPart(answer, exercise);
handleDivideEncoding(exercise);
if (getInfixExpressionAnswer(exercise) == stringToImproperFraction(answer)
) {
correctID.push_back(problemID);
} else {
wrongID.push_back(problemID);
}
}
while (fgets(exercise, 256, exerciseFile)) {
problemID++;
wrongID.push_back(problemID);
}
printID(pFile, const_cast<char*>("Correct"), correctID);
printID(pFile, const_cast<char*>("Wrong"), wrongID);
fclose(pFile);
printf("Check answer done!\n");
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
std::queue<std::string> transformInfixExprToSuffixExpr(
const std::string &InfixExpression) {
std::stack<char> temp;
std::queue<std::string> result;
for (int i = 0; i < InfixExpression.length(); i++) {
char cc = InfixExpression[i];
if (cc == ' ') {
continue;
} else if (cc == '(') {
temp.push(cc);
} else if (cc == ')') {
char c;
do {
c = temp.top();
temp.pop();
if (c != '(') {
result.push(charToString(c));
}
} while (c != '(');
} else if (cc == '+' || cc == '-') {
while (!temp.empty()) {
char c = temp.top();
if (c != '(') {
result.push(charToString(c));
temp.pop();
} else {
break;
}
}
temp.push(cc);
} else if (cc == 'x' || cc == '\xc3') {
i += cc == '\xc3';
while (!temp.empty()) {
char c = temp.top();
if (c == 'x') {
result.push(charToString(c));
temp.pop();
} else if (c == '\xc3') {
result.push(charToString(c));
temp.pop();
} else {
break;
}
}
temp.push(cc);
} else {
std::string s;
while (i < InfixExpression.length()) {
char c = InfixExpression[i];
if (isdigit(c) || c == '/' || c == '\'') {
s += c;
i++;
} else {
i--;
break;
}
}
result.push(s);
}
}
while (!temp.empty()) {
char c = temp.top();
temp.pop();
result.push(charToString(c));
}
return result;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
ImproperFraction getSuffixExpressionAnswer(
std::queue<std::string> suffixExpression) {
std::stack<ImproperFraction> sta;
while (!suffixExpression.empty()) {
std::string s = suffixExpression.front();
suffixExpression.pop();
if (isOperator(s)) {
ImproperFraction a = sta.top();
sta.pop();
ImproperFraction b = sta.top();
sta.pop();
if (s[0] == 'x') {
sta.push(a * b);
} else if (s[0] == '\xc3') {
sta.push(b / a);
} else if (s[0] == '+') {
sta.push(a + b);
} else {
sta.push(b - a);
}
} else {
sta.push(stringToImproperFraction(s));
}
}
return sta.top();
}
|
测试报告
首先是各种参数错误的测试
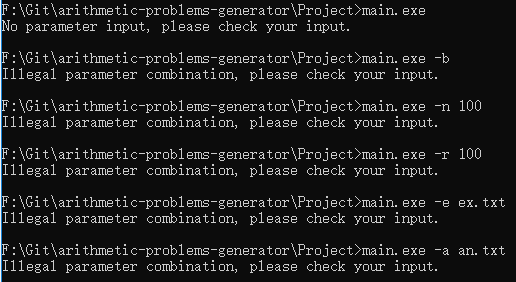
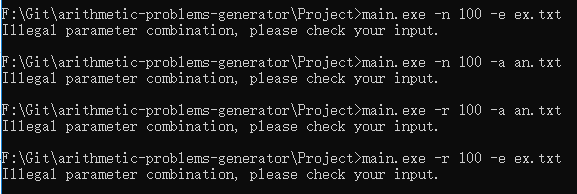

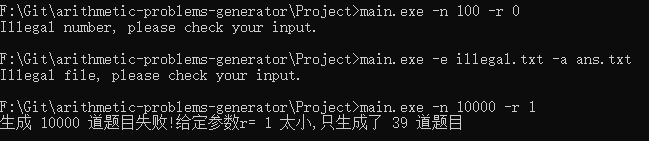
接着是传入正确的参数的测试
生成题集的测试:


给定的题目文件和答案文件,判定答案中的对错测试:

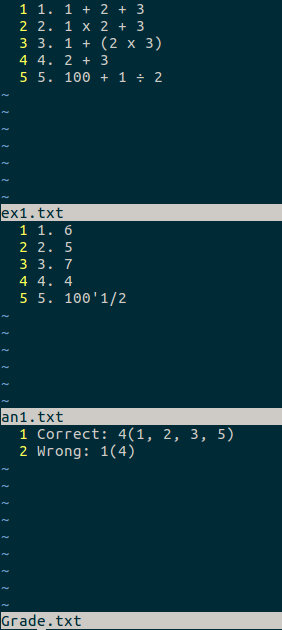
效能分析
本程序主要由生成运算题目和检查答案正确性两个模块,因此效能分析也主要针对这两个模块进行。
1. 生成运算题目
生成一百万条题目时候的时间占比情况:

由上图看出了,占用时间最多的前五个函数为
- questionSetGenerate
- gcd
- addbrackets
- digToString
- ImproperFraction
其中,questionSetGenerate是生成运算题目的函数入口,占用时间最长。gcd是在题目运算过程,分数通分时进行调用的,具体实现是辗转相除法。addbrackets是在生成题目的过程给表达式添加括号。digTostring是在生成题目的过程将数字转化为字符串。ImproperFraction是真分数的类名,由于生成的表达式中普遍含有真分数,所以多次调用了它的构造函数。
2. 检查答案正确性
检查五十万条题目时的时间占比情况:

由上图可以看出,占用时间最多的前五个函数为:
- gcd
- stringToImproperFraction
- __deque_buf_size
- transformInfixExprToSuffixExpr
- _Deque_base
其中,gcd用于运算过程的通分,stringToImproperFraction用于将字符串转化为真分数, transformInfixExprToSuffixExpr用于将中缀表达式转化为后缀表达式。另外两个函数是系统函数。
因此,假如要优化效能的话,可以优先在源代码追踪一下上述函数,看能否减少这些函数的调用或者优化其实现方式。
PSP
| PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
60 |
50 |
| · Estimate |
· 估计这个任务需要多少时间 |
60 |
50 |
| Development |
开发 |
965 |
1545 |
| · Analysis |
· 需求分析 (包括学习新技术) |
50 |
100 |
| · Design Spec |
· 生成设计文档 |
25 |
35 |
| · Design Review |
· 设计复审 (和同事审核设计文档) |
25 |
35 |
| · Coding Standard |
· 代码规范 (为目前的开发制定合适的规范) |
25 |
65 |
| · Design |
· 具体设计 |
60 |
80 |
| · Coding |
· 具体编码 |
360 |
415 |
| · Code Review |
· 代码复审 |
60 |
150 |
| · Test |
· 测试(自我测试,修改代码,提交修改) |
360 |
665 |
| Reporting |
报告 |
110 |
130 |
| · Test Report |
· 测试报告 |
60 |
80 |
| · Size Measurement |
· 计算工作量 |
25 |
25 |
| · Postmortem & Process Improvement Plan |
· 事后总结, 并提出过程改进计划 |
25 |
25 |
| 合计 |
|
1135 |
1725 |
项目小结
有待改进的地方
溢出问题:当给定r过大的时候,将会导致最终运算结构的分母溢出,而造成的数据错误
目前方案:检查溢出,将发生了溢出的表达式删除
更佳方案:使用大数的运算,就可以完美避免数据溢出的问题
生成题目不够友好:当给定数据范围r稍稍有点大的时候,最终答案的分母可能超过一亿
目前方案:不处理
更佳方案: 暂无
死循环生成题目: 当给定题数过大且给定限制太小时,无法生成要求的题目数量, 导致进入死循环
目前方案: 设置时间戳time,只生成1000000次表达式,再进行合法性判断,但也导致有可能无法生成要求题目数量
更佳方案: 暂无
开发项目中发生的问题
- 一开始的时候是选择暴力深搜生成题集,再随机选取表达式输出,但是生成的效果来看,题目并不是很随机,例如前两个数字是固定死的,思前想后,觉得还是使用rand()随机生成效果更佳
- 在最开始设计方案的时候,还是思虑的不够多,以至于后面的代码复审(Debug)工作做了很多,远超过代码编写部分
- 还有各种人性化的设置,如参数错误提示,程序运行结果显示之类话语并没有想到,但是一个软件,一个项目最终都是面向于人群大众,人性化的设置是必须的
团队之中的闪光点
- 良好的代码风格: 在一开始我们就约束好了团队的代码风格,在后续的代码编写之中我们也能够很好的参照代码风格进行书写,因此在代码复审的时候我们也能够很好的查阅对方的代码
- 不错的代码能力: 想定思路学习知识之后,可直接进行代码的实现,基本上不会出现一些逻辑错误.后面出现的bug也是因为设计的时候稍稍不够考虑细节,一旦出现bug,都能够立马找到bug和想到相应的修复方案
- 互帮互助: 在一开始我们就进行了分工,一个人主要负责对给定的题目文件和答案文件进行答案校对、参数组合正确性的检测,另一个人负责了题集的生成部分。并且在最后,一起测试并撰写了博客。
通过这次项目,我们实践了结对编程,提高了沟通能力,加强了团队合作的能力。